

现在的位置:主页 > 综合新闻 >
解放军总医院赵敏:多模态医学数据分析面临四
【作者】:网站采编【关键词】:【摘要】:随着医疗信息化的快速发展以及医疗设备的更新迭代,海量且类型多样的医学数据应运而生。 根据目前医学数据所展示的具体信息和形式,我们可以将其大致分为三大类: 1.临床文本数
随着医疗信息化的快速发展以及医疗设备的更新迭代,海量且类型多样的医学数据应运而生。
根据目前医学数据所展示的具体信息和形式,我们可以将其大致分为三大类:
1.临床文本数据。主要包括血红蛋白、尿常规等结构化的检验数据,以及医生记录的患者主诉、病理文本等非结构化的文本数据;
2.影像、波形数据。包括超声图像、CT图像、核磁共振图像等影像数据和心电图、脑电图等信号数据;
3.生物组学数据。按照不同的分子层面又可以分为基因组、转录组、蛋白组等。
获取患者相关数据的每类方式均为一种数据模态,不同模态的医学数据都从特定的角度提供了患者的诊疗信息,信息间既有重叠又有互补,结合多种类的医学信息则进一步提高了诊断治疗的准确性。
在大数据时代背景下,算法工具和数据分析技术的不断创新也极大地促进了多模态数据融合分析的发展。近十年来国家自然基金项目医学科学类中,关于多模态医学研究项目数量逐年稳步增多,资助金额也呈增长趋势(图1)。尽管如此,基于多模态数据的智能诊疗大部分仍处于理论方法研究阶段,距离实际临床应用还有一段距离。
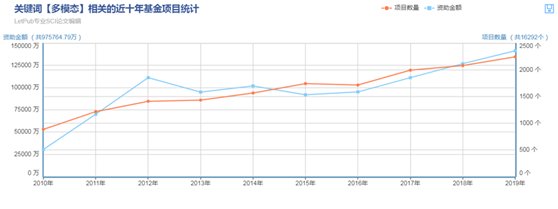
图1 近十年多模态医学研究国家自然基金项目统计
在多模态医学数据研究方面,我们小组正在利用口腔癌多模态数据进行初步探索。口腔癌是发生于口腔黏膜的恶性肿瘤,是世界十大最常见癌症之一,具有发病率高、病情发展快和易转移等特点。目前临床诊断仅基于医生触诊和CT等影像检查,并不能对颈部淋巴结转移情况进行准确评估。针对上述问题,我们的研究目标是综合利用影像组学、基因组学、临床信息等不同维度的表征,实现术前预测口腔鳞状细胞癌患者是否发生颈部淋巴结转移,以指导治疗方案的恰当选择。
口腔癌淋巴结转移研究技术路线如下(见图2):
首先将我院近十年行颈淋巴结清扫术的口腔鳞状细胞癌患者分为发生和未发生颈部淋巴结转移两组,根据患者ID提取病理检验和CT、MRI影像等数据,然后通过自然语言处理技术对病理文本进行特征抽取,得到淋巴结大小、活动度等临床特征集;
将人工标注后的医学影像通过深度学习技术提取图像的纹理特征等量化后得到影像特征集,基于该部分患者的临床和影像特征建立转移预测模型。
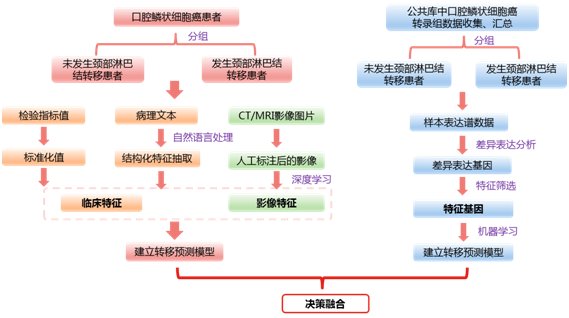
图2 口腔癌淋巴结转移研究技术路线
由于缺少患者的组学信息,在基因组学数据方面,我们首先对公共数据库中的数据进行重新分组和再分析,以挖掘出与淋巴结转移相关的特征基因并建立预测模型。
最后对两个模型进行决策融合。目前该项目已有部分结果,但尚在进行中,因此暂不作展示。最后结合我们实际工作经验,发现目前在多模态医学数据具体分析和应用中主要面临着如下问题:
1.数据完整性差。同时具备患者的检查检验信息以及生物组学信息等多模态数据的有效样本少,对于医院来说基因组学信息尚未整合到电子病历系统中,而测序公司有大量的测序数据但没有患者的相应的临床资料,所以目前的大多数研究都是基于小样本建立诊断预测模型;
2.数据内部存在异质性。在数据处理过程中我们发现检验数据因为检验仪器设备不同而引起标准不同,影像数据又存在着设备的品牌不同导致所采集的医学影像间存在差异,生物组学数据不同的样本处理方式及测序平台也不能直接进行比较分析;
3.多模态、跨模态医学数据的融合算法研究尚未成熟;
4.研究协作机制不完善。多模态医学数据融合分析属于多学科交叉领域,需要临床医生、统计分析工程师、算法工程师、生物信息工程师等各学科背景的人反复沟通交流确定研究方案。
由此可见,多模态医学数据融合分析任重而道远。
(注:本文作者 赵敏,中国人民解放军总医院医学大数据研究中心工程师)
【来源:健康界】
声明:转载此文是出于传递更多信息之目的。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本网联系,我们将及时更正、删除,谢谢。 邮箱地?/p>
文章来源:《医学信息》 网址: http://www.yxxxbjb.cn/zonghexinwen/2020/0923/795.html
上一篇:男子电影院时突发癫痫浑身抽搐 四名医学研究生
下一篇:成为医学巨匠的17条原则